

用Optuna进行Pytorch超参数调优教程
使用Pytorch构建深度学习模型的一系列指南中的第四篇来啦!Optuna作为主要面向深度学习超参数调优开发的框架,在实现之初就考虑到了大型模型参数调优的各种实际情况,并逐一针对它们设计了解决方案。今天学姐就带大家学习如何使用Optuna进行Pytorch超参数调优。
前三篇传送门:
Optuna是一个自动超参数搜索的超参数优化框架,可应用于机器学习和深度学习模型;Optuna使用了采样和剪枝算法来优化超参数,所以非常快速和高效;它还可以通过直观的方式动态构建超参数搜索空间。
本篇文章的重点是结合Pytorch和Optuna,在MNIST数据集上找到性能最佳的CNN模型。我将逐步展示应用Optuna所需的函数和要调整的超参数。
先安装Optuna库
!pip install optuna之后导入库和数据集
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import random_split
from torch.nn import functional as F
import torchvision
from torchvision import datasets,transforms
import torchvision.transforms as transforms
import optunaimport os
DEVICE=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
CLASSES=10
DIR=os.getcwd()
EPOCHS=10
train_dataset=torchvision.datasets.MNIST('classifier_data', train=True, download=True)
m=len(train_dataset)transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor()])
train_dataset.transform=transform接着将卷积神经网络一起定义到要调整的超参数
class ConvNet(nn.Module):
def __init__(self, trial):
# We optimize dropout rate in a convolutional neural network.
super(ConvNet, self).__init__()
self.conv1=nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2)
self.conv2=nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2)
dropout_rate=trial.suggest_float("dropout_rate", 0, 0.5,step=0.1)
self.drop1=nn.Dropout2d(p=dropout_rate)
fc2_input_dim=trial.suggest_int("fc2_input_dim", 32, 128,32)
self.fc1=nn.Linear(32 * 7 * 7, fc2_input_dim)
dropout_rate2=trial.suggest_float("dropout_rate2", 0, 0.3,step=0.1)
self.drop2=nn.Dropout2d(p=dropout_rate2)
self.fc2=nn.Linear(fc2_input_dim, 10)
def forward(self, x):
x=F.relu(F.max_pool2d(self.conv1(x),kernel_size=2))
x=F.relu(F.max_pool2d(self.conv2(x),kernel_size=2))
x=self.drop1(x)
x=x.view(x.size(0),-1)
x=F.relu(self.fc1(x))
x=self.drop2(x)
x=self.fc2(x)
return x在Optuna中,目标是最小化/最大化目标函数,它将一组超参数作为输入并返回验证分数。对于每个超参数,需要考虑不同范围的值。
优化的过程称为研究,而对目标函数的每次评估称为试验。“Suggest API”在模型架构内被调用,为每个试验动态生成超参数。
可以定义超参数范围的函数:
- suggest_int 建议为第二完全连接层的输入单元设置整数值
- suggest_float 建议dropout率的浮点值,在第二个卷积层(0-0.5,步长为0.1)和第一个线性层(0-0.3,步长为0.1)之后作为超参数引入。
- suggest_categorical 建议优化器的分类值,稍后将显示
更多资料:
https://optuna.readthedocs.io/en/v1.4.0/reference/trial.html
定义了一个函数来尝试训练集中batch_size的不同值。它将训练数据集和批大小作为输入(稍后将在目标函数中定义),并返回训练和验证加载器对象。
def get_mnist(train_dataset,batch_size):
train_data, val_data=random_split(train_dataset,[int(m-m*0.2), int(m*0.2)])
# The dataloaders handle shuffling, batching, etc...
train_loader=torch.utils.data.DataLoader(train_data, batch_size=batch_size)
valid_loader=torch.utils.data.DataLoader(val_data, batch_size=batch_size)
return train_loader, valid_loader最重要的一步是定义目标函数,它使用采样程序来选择每次试验中的超参数值,并返回在该试验中获得的验证准确度。
def objective(trial):
# Generate the model.
model=ConvNet(trial).to(DEVICE)
# Generate the optimizers.
# try RMSprop and SGD
'''
optimizer_name=trial.suggest_categorical("optimizer",["RMSprop", "SGD"])
momentum=trial.suggest_float("momentum", 0.0, 1.0)
lr=trial.suggest_float("lr", 1e-5, 1e-1, log=True)
optimizer=getattr(optim, optimizer_name)
(model.parameters(), lr=lr,momentum=momentum)
'''
#try Adam, AdaDelta adn Adagrad
optimizer_name=trial.suggest_categorical("optimizer",["Adam", "Adadelta","Adagrad"])
lr=trial.suggest_float("lr", 1e-5, 1e-1,log=True)
optimizer=getattr(optim, optimizer_name)
(model.parameters(), lr=lr)
batch_size=trial.suggest_int("batch_size", 64, 256,step=64)
criterion=nn.CrossEntropyLoss()
# Get the MNIST imagesset.
train_loader, valid_loader=get_mnist(train_dataset,batch_size)
# Training of the model.
for epoch in range(EPOCHS):
model.train()
for batch_idx, (images, labels) in enumerate(train_loader):
# Limiting training images for faster epochs.
#if batch_idx * BATCHSIZE >=N_TRAIN_EXAMPLES:
# break
images, labels=images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
output=model(images)
loss=criterion(output, labels)
loss.backward()
optimizer.step()
# Validation of the model.
model.eval()
correct=0
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(valid_loader):
# Limiting validation images.
# if batch_idx * BATCHSIZE >=N_VALID_EXAMPLES:
# break
images, labels=images.to(DEVICE), labels.to(DEVICE)
output=model(images)
# Get the index of the max log-probability.
pred=output.argmax(dim=1, keepdim=True)
correct +=pred.eq(labels.view_as(pred)).sum().item()
accuracy=correct / len(valid_loader.dataset)
trial.report(accuracy, epoch)
# Handle pruning based on the intermediate value.
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return accuracy下面创建一个study对象来最大化目标函数,然后使用study.optimize(objective,n_trials=20)进行研究,将试验次数定为20次。可以根据问题的复杂程度对其进行更改
study=optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=20)
trial=study.best_trialprint('Accuracy:{}'.format(trial.value))
print("Best hyperparameters:{}".format(trial.params))为了更容易地可视化最近5次试验中选择的超参数,我们可以构建一个DataFrame对象:
df=study.trials_dataframe().drop(['state','datetime_start','datetime_complete','duration','number'], axis=1)
df.tail(5)
性能最好的模型在第 20 次试验中获得了 98.9% 的验证准确率。上面是该试验中选择的超参数值。
有许多有趣的可视化方法可以帮助查看优化的不同方面。我们可以看到目标值如何随着试验次数的增加而增加。
optuna.visualization.plot_optimization_history(study)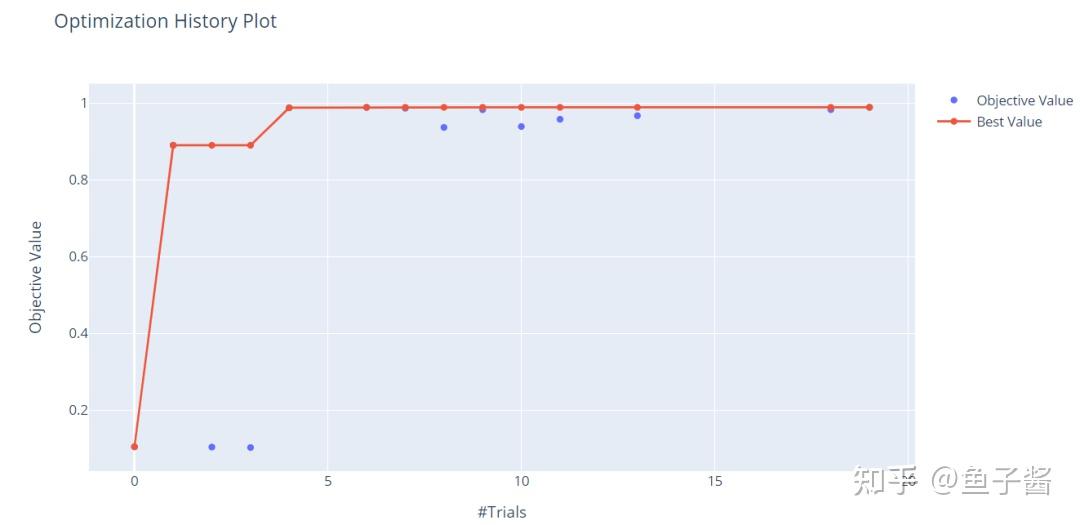
x轴是试验数据,y轴是客观值,对应于验证精度。仅通过20次试验,我们就可以看到我们获得了90%以上的高分。
我们还可以证明不同超参数之间的关系。在这种情况下,我们只关注批量大小和学习率:
optuna.visualization.plot_contour(study, params=['batch_size', 'lr'])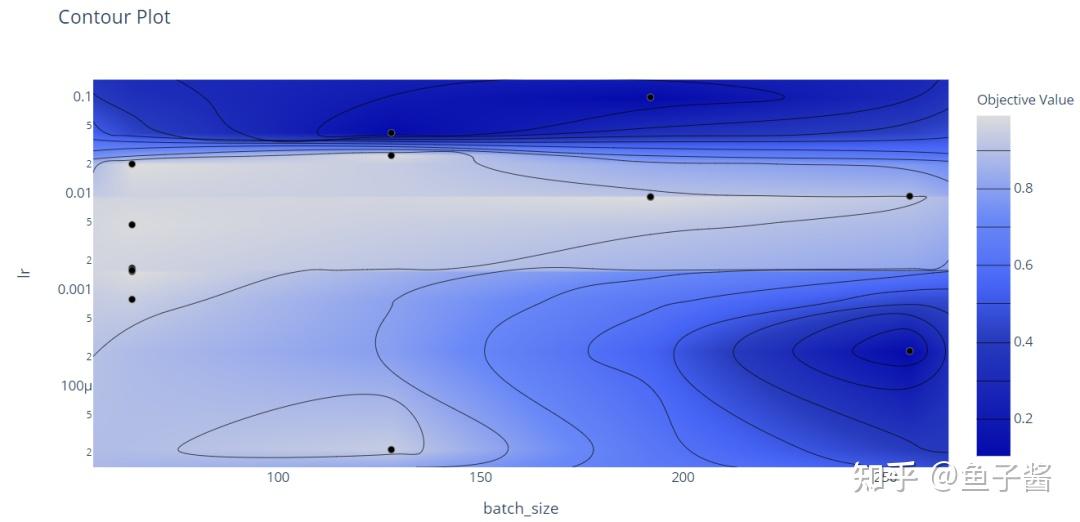
Contour Plot是一个3D图,其中第三维由目标值构成。从中心的集群(浅蓝色表示验证准确率非常高),我们可以观察到这些结果是在中等学习率(介于0.001和0.01之间)和低/中等批量大小下获得的。
使用平行坐标图,我们可以观察到所有已考虑到的优化历史:
optuna.visualization.plot_parallel_coordinate(study)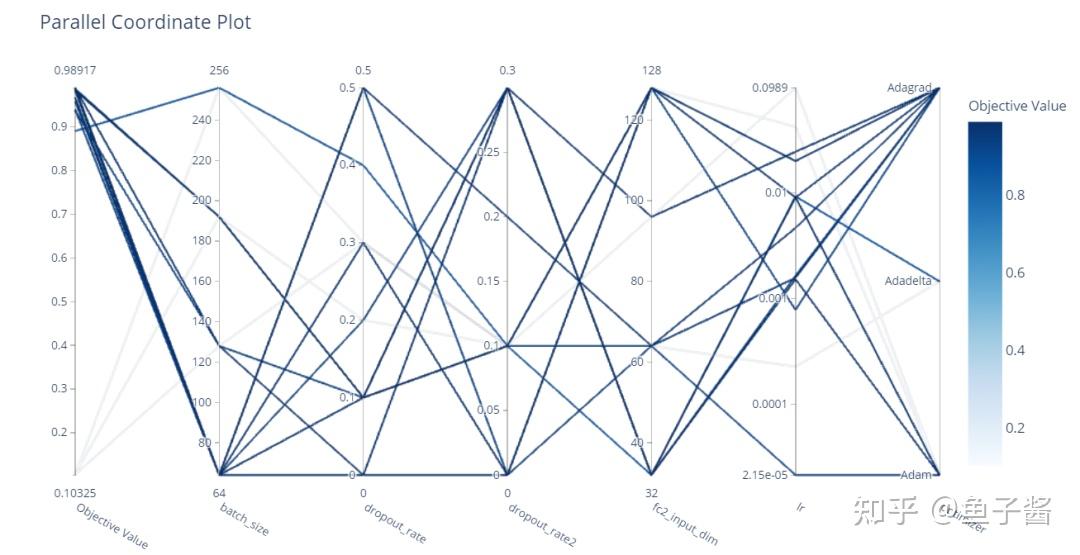
另一个有用的表示由超参数重要性构成。因此,可以了解到哪些超参数对模型的性能影响最大。
optuna.visualization.plot_param_importances(study)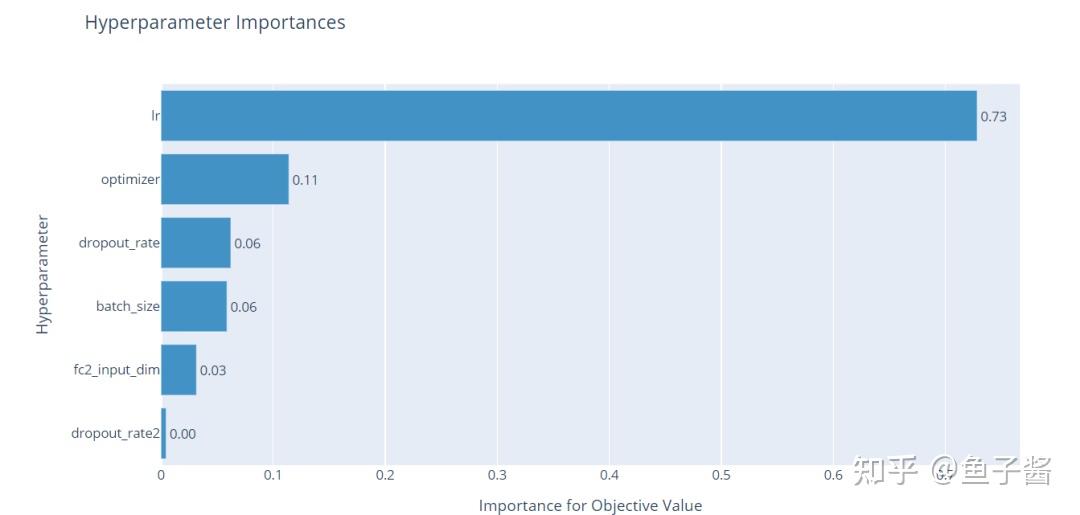
从图中可以看出,学习率对目标值的影响最大,而其他超参数对学习率的影响很小。丢失率对性能的影响很小,但仍然需要降低过拟合的风险。
希望学姐的这篇文章能够帮助你理解Optuna!
原文链接:
https://pub.towardsai.net/tuning-pytorch-hyperparameters-with-optuna-470edcfd4dc
学姐终于建群了~公众号后台回复“进群”拉你进群

分享收藏点赞在看


